
Could If-Then Commitments Help the US and China Agree on Measures for Mitigating AI Risks?
They seem like a promising place to start.

Summary
This post argues that if-then commitments—rules which map capability or risk levels to decisions about how to develop, deploy, secure or control AI systems—might help the US and China to reach an agreement on appropriate measures for mitigating AI risks.
In a broad sense, if-then commitments can be thought of as rules that state specific actions must be taken when certain conditions arise. In relation to AI, and for the purposes of this piece, the term ‘if-then commitments’ is used to refer specifically to rules which map capability or risk levels to decisions about how to develop, deploy, secure and control AI systems (following Karnofsky, 2024).
This post argues that such if-then commitments could be useful as part of a broader portfolio of approaches for helping the US and China reach an agreement on appropriate measures for mitigating AI risks. This is principally for two reasons.
First, negotiators could draw on the structure of if-then commitments by focusing negotiations on which ‘triggers’ (indicators of capability or risk) should be met with which ‘safeguards’ (mitigation measures to activate if and only if those triggers are met). As Karnofsky notes in his original piece on if-then commitments (Karnofsky 2024), this might allow them to bypass potential disagreements as to whether or when AI might become dangerous.
Second, negotiators could draw on the precedent of if-then commitments in US and Chinese AI risk management frameworks, as well as the Safety and Security section of the GPAI Codes of Practice, as a foundation for negotiations. This might help the parties reach an agreement slightly faster. If companies have already adopted mechanisms requested by the EU AI Act Code of Practice, the additional compliance burden may also be minimal.
That said, if-then commitments have limitations. Crucially, negotiations could stall due to lack of consensus around appropriate trigger thresholds and safeguards. Capabilities evaluations might be unreliable unless carefully implemented. As with other possible structures for an agreement, verifying that a company had not internally developed a particular model would face considerable logistical challenges and costs.
Overall, if-then commitments look most promising as a framework for US-China agreements in worlds where:
There is significant disagreement or confusion between or within national governments as to when or whether particular AI risks will emerge.
Experts are largely in agreement as to suitable ‘trigger thresholds’ or ‘safeguards’ for particular risks, or are willing and able to develop expertise, negotiate and compromise on these.
Frontier AI companies in both the US and China are proactively improving their risk management frameworks based on if-then commitments, with support from government actors.
If-then commitments look less promising in worlds where:
There is overwhelming agreement within and between governments as to the risks from AI systems (perhaps due to concerns about red lines having been crossed, or a warning shot).
Experts still have broad disagreements about exact ‘trigger thresholds’ or ‘appropriate safeguards’ for particular risks, and are unwilling or unable to reach a consensus about these.
Frontier AI safety frameworks or equivalent risk management protocols are insufficiently well-developed to provide useful precedent, or are perceived as overly partisan.
In my view, there is currently substantial disagreement and confusion within national governments about when—or whether—specific AI risks will emerge. However, experts also disagree widely on the capability thresholds that should trigger particular safeguards. My main uncertainty about whether if-then commitments are worth pursuing is how hard it will be for the US and China to reach a consensus on specific triggers and safeguards.
On balance, for now, my view is that if-then commitments seem like a fairly promising starting point for US-China agreements. For example, it does not seem ridiculous to imagine that both the US and China could at some point in the near future reach a consensus as to what sorts of capabilities could substantially uplift a novice actor in creating a bioweapon (Karnofsky, 2024), and agree to restrict AI companies from releasing such a model to the public. Whilst not sufficient to mitigate all risks from AI, such an agreement could be a step in the right direction, strengthening safeguards without placing much more of a burden on frontier AI companies than their existing risk management frameworks and potential EU AI Act compliance already entails.
That said, if-then commitments are not a silver bullet. My main uncertainty about whether if-then commitments are worth pursuing is how hard it will be for the US and China to reach a consensus on specific triggers and safeguards for particular threat models (this may be the topic of a future blog post). Other approaches based on compute thresholds, usage red lines, or emergency responses should also be explored. Should triggers and safeguards prove intractable to reach consensus on, these approaches might prove more tractable pathways for a bilateral agreement.
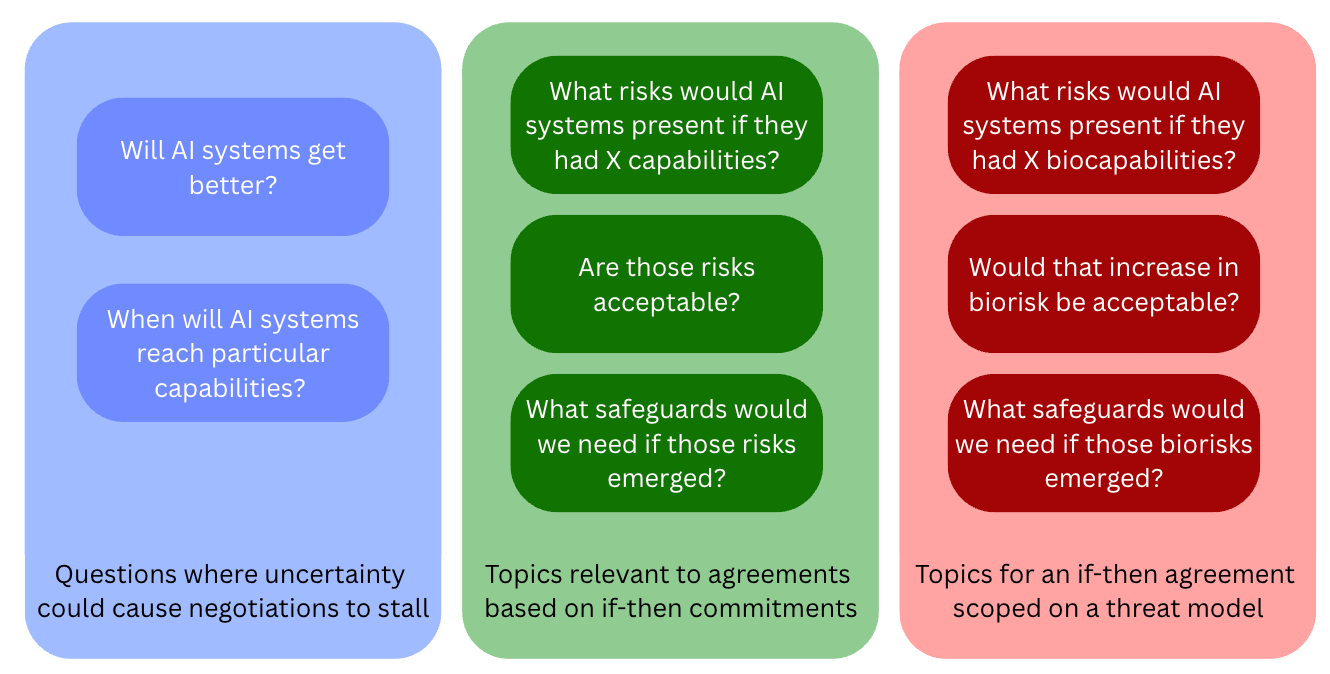
The rest of this piece explores this argument in more depth, highlighting some advantages and disadvantages of using if-then commitments for reaching agreements between the US and China on AI risks. The discussion is quite high-level, and many important problems are reserved for the ‘open problems’ section at the end. The goal of this piece is to serve as a starting point to show that if-then commitments might be a useful framework for structuring agreements between the US and China, and worthy of further consideration.
Note: This post does not argue that agreements between the US and China should function like current safety frameworks. For example, it might not make sense for such agreements to be renegotiated regularly in the way that current safety frameworks are, or to focus on a small and medium-level as well as greater risks. It also does not discuss the wider space of conditional clauses possible in international agreements which might be thought of as ‘if-then commitments’ in the general use of the term, such as: exit clauses, suspension clauses, clauses that come into effect depending on the number of signatories, renegotiation clauses, or carve outs. I also keep the discussion scoped to a US-China agreement only, without considering the possible value of international agreements involving other actors.
What are if-then commitments?
In general, if-then commitments are rules that state specific actions must be taken when certain conditions arise. In relation to AI, the term ‘if-then commitments’ is primarily used (following Karnofsky, 2024) to refer to rules which map capability or risk levels to decisions about how to develop, deploy, secure and control AI systems. For example:
If an AI model has capability A, we will not release it publicly.
If a model is deemed to create an uplift in risk that exceeds a threshold B, we will cease all further training.
If an AI model has capability X, we will release it publicly if and only if risk mitigations Y are in place.
To take a concrete example from Karnofsky, 2024:
“If an AI model has the ability to walk a novice through constructing a weapon of mass destruction, then it should not be released to the public unless we can ensure that there are no easy ways for consumers to elicit this behavior.”
This analysis will focus on evaluating whether these commitments are suitable for US-China agreements, separate from their existing corporate or domestic uses. That said, if-then commitments form an important part of the risk management frameworks at some frontier AI companies in the US (e.g. Anthropic 2025, Google DeepMind 2025, OpenAI 2025) and China (e.g. Shanghai AI Lab and Concordia AI, 2025), as well as the Safety and Security section of the GPAI Codes of Practice (GPAI Code of Practice, 2025). The advantages of this are discussed more in the following section.
Strengths of if-then commitments
Central claim: If-then commitments might allow governments who disagree about when or whether AI risks will emerge to agree on measures to mitigate risks (particularly ones that seem less likely, or further in the future)
International agreements involve multiple governments, and potentially many parties with different beliefs about how AI capabilities will develop and the risks that this may present. The uncertainty of AI progress could make it challenging to reach agreement about how AI capabilities will develop and what risks it might present. However, there might be much more agreement between these actors about what should happen if a certain capability or risk threshold was hit. For instance, we might imagine that:
The parties disagree about whether future AI systems will be capable enough to help assist an individual actor to build a weapon of mass destruction––but if they saw sufficient evidence that AI models were capable enough to do this, they would likely agree that such systems should not be released publicly.
The parties disagree about whether future AI systems will be able to automate AI research and development––but they agree that if AI systems could perform these tasks, frontier AI companies should be transparent about this.
If-then commitments could allow for compromise where not otherwise possible. As Karnofsky noted in his 2024 piece on the subject, unconditional agreements that require costly action might be vetoed by states that don’t believe that current evidence for AI risks is definitive (Karnofsky, 2024). However, the two parties could make an if-then commitment: they could agree to implement safeguards if certain pre-specified conditions were met.
They could also increase the willingness of governments to take costly action on lower-probability or further-future events. Government actors are often reluctant to agree to costly safeguards for risks they view as unlikely or far in the future. If-then commitments could make such agreements more feasible by ensuring that obligations only become burdensome if credible evidence of the relevant danger actually emerges. By structuring commitments so that meaningful action is triggered only when predefined indicators are met, states may be more willing to take costlier action in preparation for risks that are low-probability or longer-term (categories that might substantially overlap in practice).
Secondary claim: Drawing on the precedent of if-then commitments in existing safety frameworks and legislation could make it easier to reach more robust agreements more quickly.
It would be useful if the parties responsible for conceptualising and negotiating an agreement could draw on existing best-practices when doing so, even if such best-practices were still relatively nascent. The advantage of if-then commitments here is that they are relatively well established as a governance tool in both the US and China. Similar mechanisms form the basis of Chinese frontier AI risk management frameworks (e.g. Shanghai AI Lab and Concordia AI, 2025), as well as voluntary AI safety and security frameworks used by a variety of Western AI companies (e.g. Anthropic 2025, Google DeepMind 2025, OpenAI 2025).
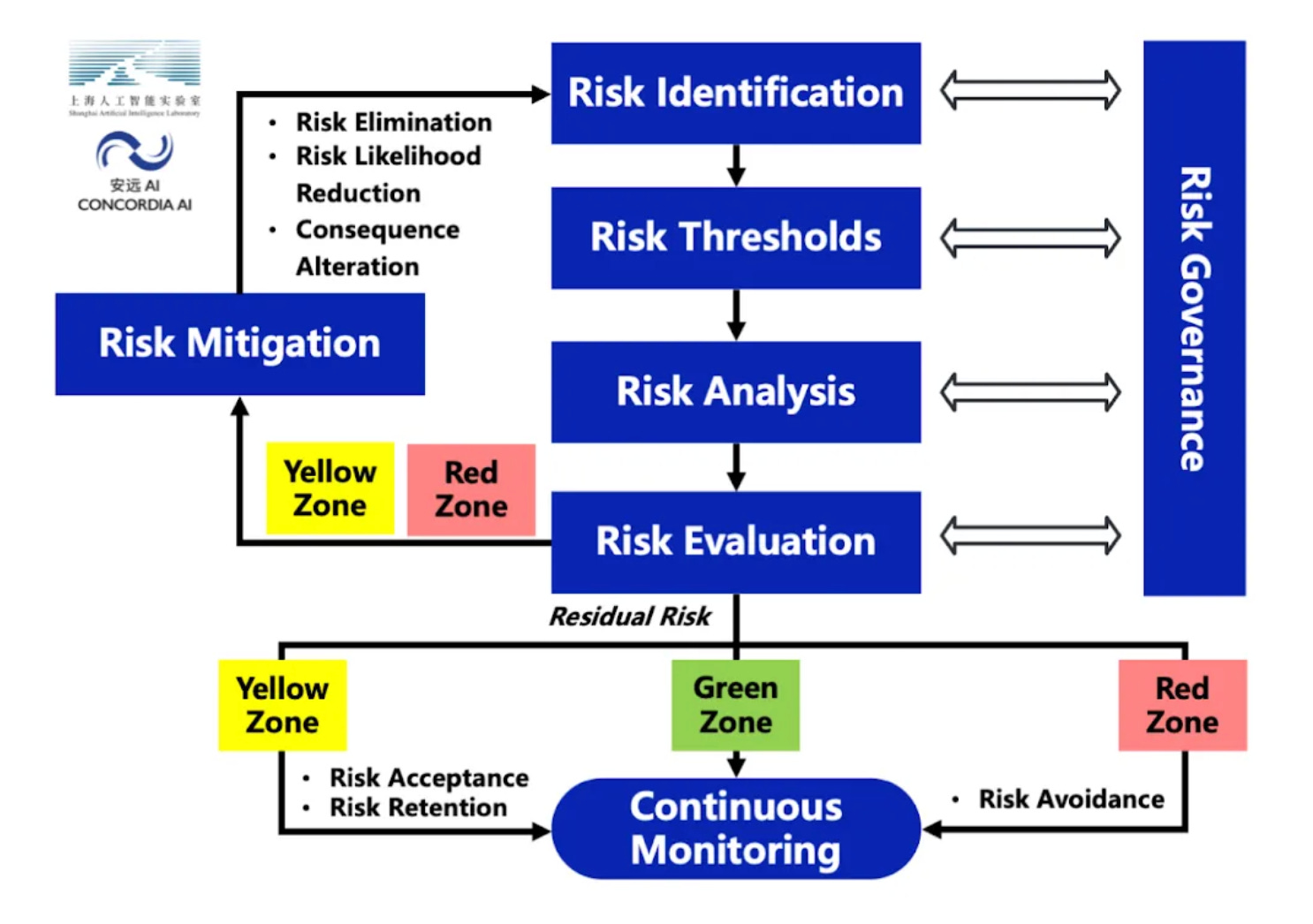
We might expect more AI system providers to develop risk management frameworks over time, especially as more provisions of the EU AI Act become enforceable (EU AI Act).
Building on the if-then commitments in these frameworks could have a number of advantages. The set of precedents in US and Chinese risk frameworks could provide a foundation for negotiators to point to when seeking consensus. Safety frameworks (and the accompanying literature of criticisms) already constitute a body of practices for thinking about AI risks and how triggers and safeguards should be operationalised, placing a lower bound on how (in)effective an agreement might be. Finally, if companies have already adopted mechanisms requested by the EU AI Act Code of Practice, the additional compliance burden may also be minimal.
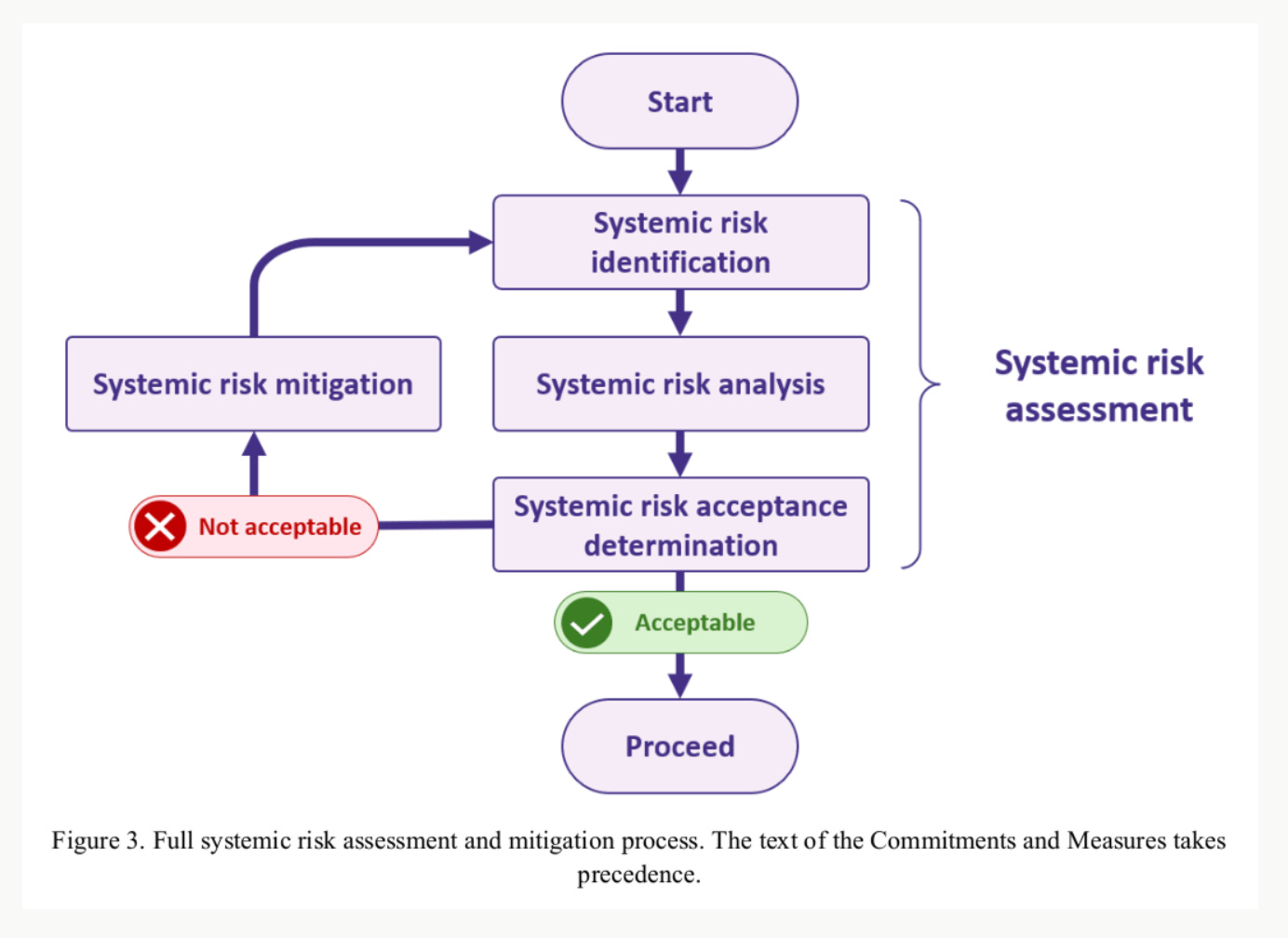
That said, the value that safety frameworks could provide to a US-China agreement could be limited. How many Chinese AI companies will sign up to the Code of Practice is still unclear. If if-then commitments are associated with Western safety frameworks, then Chinese stakeholders may resist them. Even if negotiators decided to draw directly from safety frameworks, they would still have to agree which safety frameworks best represented their interests, or what differences between individual safety frameworks were acceptable. Finally, clauses in contemporary safety or risk management frameworks may not be sufficient to mitigate risks, well operationalised, or appropriate for verification in an international context: further development may be required.
Weaknesses and limitations of if-then commitments
It could still be hard to identify and build agreement around adequate trigger thresholds
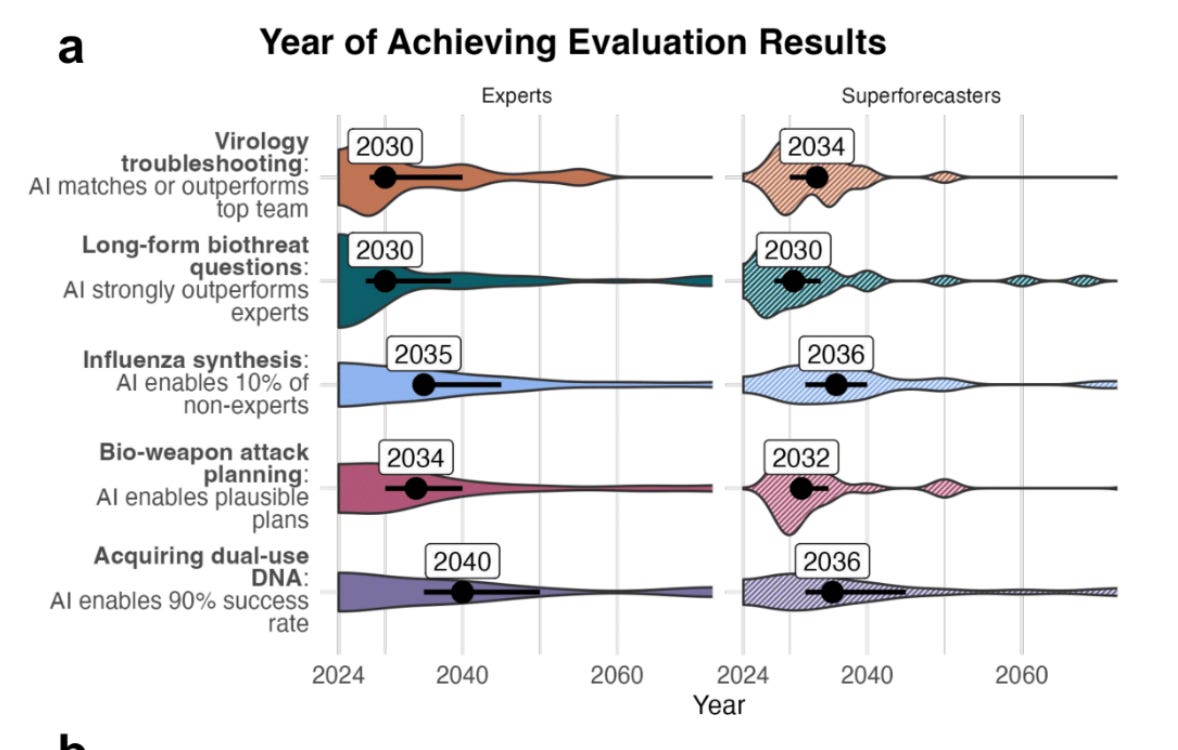
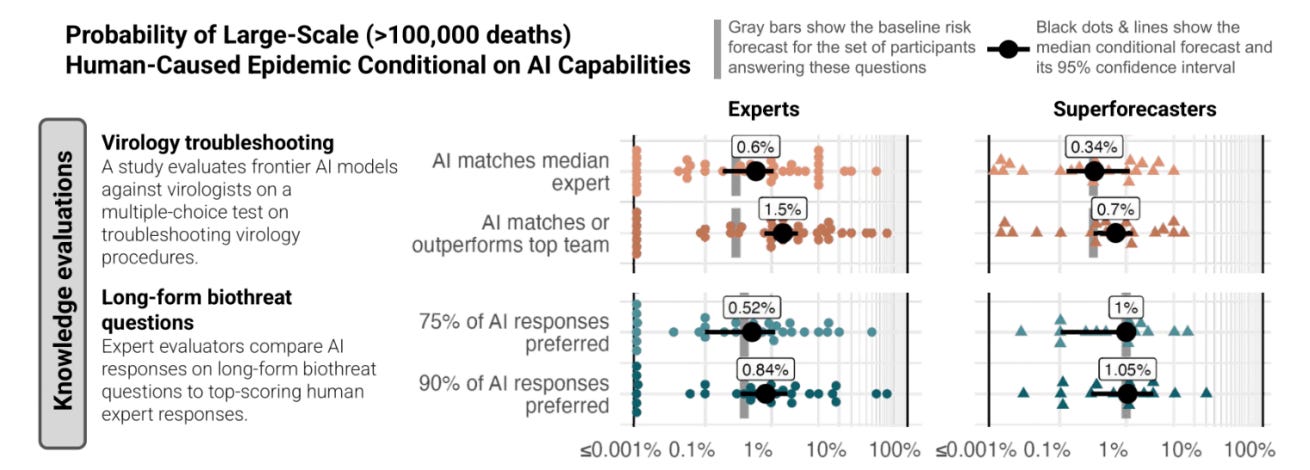
It is often unclear what level of capability will correspond to what degree of uplift in risk. For example, in a recent study, experts and superforecasters demonstrated substantial disagreement (~3-4 order of magnitude) as to how AI models might increase risks, even when they agreed about the capabilities of a model on particular virology-related benchmarks (Williams et al., 2025). A recent paper found similar uncertainty as to what thresholds should be appropriate for governing AI systems (Schuett et al., 2025). Global red lines for AI have been widely-supported, but have proved harder to deliver on (AI Red Lines, 2025).
In lieu of an established consensus for appropriate trigger thresholds, one party might push for more cautious trigger thresholds, whereas another might push for ones that grant them the licence to develop capabilities further. These disagreements might be difficult to resolve, making an agreement harder to reach. It might also be the case that thresholds which are decided on are over- or under-cautious, making the agreement too burdensome, or ineffective. It might also be that even with technical clarity, parties strategically prefer ambiguous triggers to preserve freedom of action.
As more AI companies adopt safety frameworks, it is possible that best practices converge on a few key benchmarks. Otherwise, there are a few ways one could mitigate these obstacles. Further uplift studies could try to identify appropriate trigger thresholds by providing clearer evidence as to the uplift that different levels of capability provide. Track II/Is could serve a role to develop this consensus internationally. Failing consensus, agreements could also have ‘renewal’ or ‘sunset’ clauses which ensure that inadequate trigger thresholds are not locked in in perpetuity. All in all, it seems likely that an agreement based around trigger thresholds would face substantial challenges in identifying and reaching consensus.
Evaluations are nascent, slow, and could be unreliable
One way to operationalise capabilities thresholds would be to use benchmark scores. However, this might face some problems in principle. Without further developments, benchmarks might be poor proxies for real-world harms. Benchmark scores might only reflect lower bounds for capabilities (Barnett and Thiergart, 2024), and be sensitive to small differences in prompting, framing and implementation. Situationally aware models might affect the reliability of testing results (Schoen et al., 2025). Although both the US and China have national bodies with experience running evaluations, the respective bodies are relatively nascent (CAISI, 2025; Concordia and Shanghai AI Lab, 2025).

There are a few other reasons why proposing capabilities thresholds in the form of specific benchmark scores might be especially challenging in US-China agreements. One problem is longevity. It might be difficult to renegotiate benchmarks for an agreement, but existing benchmarks might be saturated within several years (Epoch, 2025), or become contaminated. Another problem is consensus. It’s possible to imagine the US and China both wanting different (perhaps privately developed) benchmarks to be used as an international standard. It could be difficult to reach an agreement on these.
One way to get around this might be to have an OR statement that involves multiple trigger clauses. This could have two main advantages. First, it would allow compromise between different benchmarks in the absence of trust. For instance: if a model shows this capability on X benchmark (built by the Center for AI Standards and Innovation), or it shows this capability on Y benchmark (built by Shanghai AI Lab), then it could be considered high-risk. Second, it might allow triggers to be more robust and long-lasting. If one trigger failed (for instance, a benchmark became saturated, or it was possible to reverse goodhart against it) then another trigger could still work. For example: if a model gets above 80% on this well-established benchmark or above 20% on this extremely difficult benchmark, then the model would be considered high-risk. New benchmarks could be added to and removed from a ‘benchmark suite’ over time in order to keep the thresholds relevant. (Such a ‘suite of benchmarks’ could be similar to Epoch’s AI Capabilities Index).
Capabilities detection and verification could remain challenging and costly for agreements that better mitigate risks
We can imagine two types of if-then commitments (based on AI capabilities) with different demands on verification:
If-then commitments regarding model deployment. E.g. If a model exceeds a particular capability score of a particular benchmark, then the party will not publicly release it.
If-then commitments regarding model development. E.g. If a model exceeds a particular capability score on a particular benchmark, then the party will not privately develop it any further.
Both of these have different advantages and disadvantages.
If-then commitments regarding model deployment would be somewhat effective at mitigating risks, since it would prevent misuse by the set of actors using publicly released open or closed source models. It would also be relatively straightforward to verify. When models came out, third-parties could test the model on the appropriate suite of benchmarks to confirm that it was below a particular capability threshold. If the benchmark suite needed to be kept private, then the US could test Chinese models, and vice-versa. One challenge might be if evaluations required an unsafeguarded version of the model; in this case, perhaps both countries could share the model with a trusted third country to perform the evaluations.
In contrast, if-then commitments regarding model development would be more effective at mitigating risks. In addition to preventing misuse by the set of actors using publicly released open or closed source models, it could also mitigate risks from scenarios where powerful AI systems are stolen by adversaries (Nevo et al., 2024), misused by the AI company (Davidson, Finnveden and Hadshar, 2025) or exfiltrate autonomously. The prevention of developing a technology would also have precedent in Chinese approaches to human gene editing (Liu, Shi and Xu, 2025).
However, this agreement would also be more costly to implement. It would necessitate evaluating models at several points throughout training—a practice that labs might already carry out internally, though current safety frameworks do not make this explicit.
It would also be challenging to verify that an AI company has not trained an AI system that exceeds the acceptable capabilities limit. It would be even harder to verify that they could not have trained such a model (which would be the gold-standard guarantee). Being able to verify this confidently without infringing on sensitive information might require on-chip or off-chip mechanisms that are a few years away from being developed (Baker et al., 2025). These may also be hard to develop buy-in around, particularly if parties regard verification mechanisms as a security risk.
There may be a tradeoff between risk-mitigating if-then agreements and those that are realistically verifiable in the near term. This need not be a major obstacle: one could start with if-then commitments tied to public release in order to build precedents for stronger agreements later. Still, it’s important not to underestimate the substantial verification work that more robust—and ultimately more consequential—agreements might require.
Conclusion and Open Problems
This post has argued that if-then commitments seem like a promising mechanism for US-China agreements for two main reasons. First, they might allow negotiators to bypass disagreements as to when or whether AI risks will emerge to find agreements on triggers and safeguards to mitigate risks. Second, if-then commitments could draw on US and Chinese company safety frameworks as well as EU AI Act Code of Practice to improve the robustness of the agreement without imposing compliance burdens relative to practices frontier AI companies already engage in.
That said, they still have limitations. Building expert consensus around capability or ‘trigger’ thresholds might be challenging. Designing and developing sufficiently discriminative benchmarks could require sustained investment. As with any agreement, clauses that prohibit certain models from being developed could better mitigate risks, but might be harder to verify.
On balance, if-then commitments seem like a somewhat promising area for US-China agreements. For example, it seems conceivable to imagine that both the US and China could reach a consensus as to what sorts of capabilities could substantially uplift a novice actor in creating a bioweapon (Karnofsky, 2024), and agree to restrict AI companies from releasing such a model to the public. Whilst not sufficient to mitigate all the risks from AI that might be concerning, such an agreement could strengthen safeguards to mitigate risks without placing much more of a burden on frontier AI companies than their existing risk management frameworks and potential EU AI Act compliance already entail.
That said, my main crux here is whether it is possible to build consensus between the US and China around clear triggers and safeguards for a few concrete threat models. This may be a question for future blog posts to explore.
Do you have ideas relating to AI geopolitics and coordination? Send us your pitch.
 | A guest post by
|
"They could also increase the willingness of governments to take costly action on lower-probability or further-future events. Government actors are often reluctant to agree to costly safeguards for risks they view as unlikely or far in the future. If-then commitments could make such agreements more feasible by ensuring that obligations only become burdensome if credible evidence of the relevant danger actually emerges. By structuring commitments so that meaningful action is triggered only when predefined indicators are met, states may be more willing to take costlier action in preparation for risks that are low-probability or longer-term (categories that might substantially overlap in practice)."
I think the main limitation of this approach is that it is reactive, and that there might be levels of AI capability/distribution where empirical evidence of danger only emerges after it's already too late.
For example, misalignment might only appear after the misaligned AI is confident it has a decisive strategic advantage over the rest of humanity (if you endorse the sharp left turn model). The only ways to avoid this are to either slow your own AI project or sabotage those abroad preemptively, both of which carry large political costs. You might also get similar problems with infosec requirements: if they're only imposed after the final model is tested and proven dangerous, there might be months during this testing or near the end of the training run where the model is vulnerable to theft despite being dual-use.
On the other hand, I think it might function quite well for some proliferation risks, since the choice to proliferate a powerful model necessarily happens after that model is developed and its capabilities become empirical. Modulo certain scenarios like self-exfiltration, the existence of these commitments would force states to examine the offense-defense balance of a given model's capabilities instead of leaving that decision in the hands of private labs.